Erst mal ist es ein alter Hut: Eine Technologie wird reguliert und die betroffenen Unternehmen schreien „Innovationsbremse“. So passiert es zurzeit auch bei der kommenden KI-Verordnung („AI Act“), die das EU-Parlament gerade ins Ziel führt.
Nur, dass diesmal der Aufschrei besonders groß ist. In Europa macht sich Panik breit, dass hier eine „eine historische Chance wegbürokratisiert “ und im Ausland ernten wir mitleidiges Kopfschütteln. „Eine unglaublich dumme Verordnung“, poltert Paul Graham , eine Ikone im Silicon Valley, auf Twitter. Er rät europäischen Gründern, vorsorglich ins Ausland zu ziehen. „Die Wahrscheinlichkeit, dass die EU die Regulierung verpfuscht, ist einfach zu hoch.“
Was wird dem AI Act konkret vorgeworfen? Im Grunde auch hier nur was, was Regulierung immer vorgeworfen wird. Erstens, das Gesetz käme viel zu früh – Generative KI ist gerade mal in den Kinderschuhen, da wird die Technologie schon totreguliert. Außerdem habe der Gesetzgeber mal wieder keine Ahnung von der Materie. Deswegen verlangt er technisch unmögliches.
Zeit, sich den AI Act näher anzuschauen – vor allen Dingen die Änderungen, die er in den letzten Wochen bekommen hat.
Kommt der AI Act zu früh?
Von außen betrachtet wirkt es im ersten Moment so, als wäre das Gesetz eine Reaktion auf ChatGPT, aber so schnell ist die Kommission dann doch nicht. Als ChatGPT die Welt überrollte, war das Gesetz fast fertig. Denn auch vor ChatGPT waren wir längst von KI umgeben – von Algorithmen, die über unseren Social Media Feed entscheiden bis hin zur allgegenwärtigen Bilderkennung.
Die KI-Verordnung definiert deswegen sehr breit, was überhaupt Künstliche Intelligenz ist. Das Gesetz hängt den Begriff nicht an eine bestimmte Technologie (wie „Deep Learning“), sondern an vor allem an ein bestimmtes Merkmal: Autonomie. Wenn Software Entscheidungen trifft, ohne dass ein Mensch involviert ist, unterliegt sie den neuen Regelungen des AI Acts.
Diese „ungenaue“ Definition wird von vielen kritisiert. Ich halte sie für eine Stärke des Gesetzes. Autonomie ist nämlich die eigentliche Revolution der letzten Jahre: wir haben es zum ersten Mal in der Geschichte mit Werkzeugen zu tun, die eigene Entscheidungen treffen. Ob die Technik im Hintergrund aus „simplen Statistiken“ oder maschinellem Lernen besteht, ist dafür völlig wurst1 – die Grenzen sind ohnehin nicht so scharf, wie manche denken.
Das Gesetz kommt deswegen nicht zu früh, sondern ausnahmsweise nicht viel zu spät. Das Internet musste mehrere Jahrzehnte alt werden, bis sich die Regulierung auf ein passendes Datenschutzgesetz einigen konnte (dazu gleich mehr) und was auf sozialen Medien gesagt werden darf, ist bis heute nicht ganz geklärt.2
Dass die EU diesmal auf Zack ist, kann man ihr wirklich nicht vorwerfen. Allenfalls, dass sie etwas über das Ziel hinausschießt. Oder vielleicht doch nicht?
Verlangt das Gesetz technisch unmögliches?
Der AI-Act führt verschiedene Risikostufen für KI-Anwendungen ein und konzentriert sich vor allem auf „Hoch-Risiko-KIs“. Das klingt nach Computern, die die Weltherrschaft übernehmen, meint aber, dass menschliche Schicksale betroffen sind. Entscheidet also eine KI darüber, ob ein Mensch zu einem Vorstellungsgespräch eingeladen wird oder eine medizinische Behandlung erhält, ist sie hochriskant. Auch hier wieder unabhängig davon, welche Technologie diese Entscheidung trifft.
So weit so gut. Was KI-Firmen die Tränen in die Augen treibt, sind besonders die Anforderungen, die Hoch-Risiko-Unternehmen seit dem allerneusten Gesetzesentwurf erfüllen müssen:
- Betroffene dürfen erfahren, wie die KI zu ihrer Entscheidung gekommen ist. Welche Daten wurden berücksichtigt, was waren die Entscheidungskriterien?
- Hochriskante KI-Systeme müssen alles protokollieren.
- Die Betreiber müssen die möglichen Auswirkungen auf grundlegende Menschenrechte bewerten – im Vorhinein.
Wer sich nur ein wenig mit KI-Systemen beschäftigt hat, weiß, dass vor allem die „das Recht auf Erklärung“ ein Problem ist. Selbst die Programmierer ChatGPT können nicht mehr genau sagen, wie ihr KI-Bot auf eine Antwort kommt – wie sollen sie dann dieses Gesetz erfüllen können?
Und wo wir von ChatGPT sprechen: die Sprachmodelle, auf denen ChatGPT, Midjourney und die gehypten Tools der letzten Monate basieren, haben in letzter Minute einen eigenen Bereich im Gesetz spendiert bekommen. Sie müssen nun detailliert offenlegen, wie sie ihre Modelle trainiert haben und welches Copyright für die benutzten Daten gilt. Und sie müssen „vorhersehbare Risiken“ nennen, die von ihren Modellen ausgehen könnten. Übrigens gelten diese Regelungen auch für Hochschulprojekte und Open-Source-Anwendungen.
All das kann man kritisieren: zu schwierig, zu bürokratisch und vor allen Dingen unfair. Das tun die Vertreter der KI-Szene auch kräftig. Interessanterweise sagen die wenigsten, dass diese Regelungen ein unvernünftiges Ergebnis verlangen. Sie verlangen ja eigentlich nur das, was man seit jeher von jeder Technologie erwartet, die wir benutzen: wir wollen verstehen, wie sie funktioniert und abschätzen, wozu sie gebraucht werden könnte.
Nur ist das im Fall von neuen KI-Anwendungen eben besonders kompliziert. Müssen wir unsere Erwartungen herunterschrauben?
Kicken wir uns wirklich ins Abseits?
Die Reaktionen auf den AI Act erinnern sehr an die Hysterie, die die DSGVO im Jahr 2018 ausgelöst hat. Der EU wurde eine Zukunft „als dunkler Fleck in der digitalen Welt“ bescheinigt und ja, auch ich, war tierisch genervt von den Blüten, die die DSGVO erst einmal trieb.
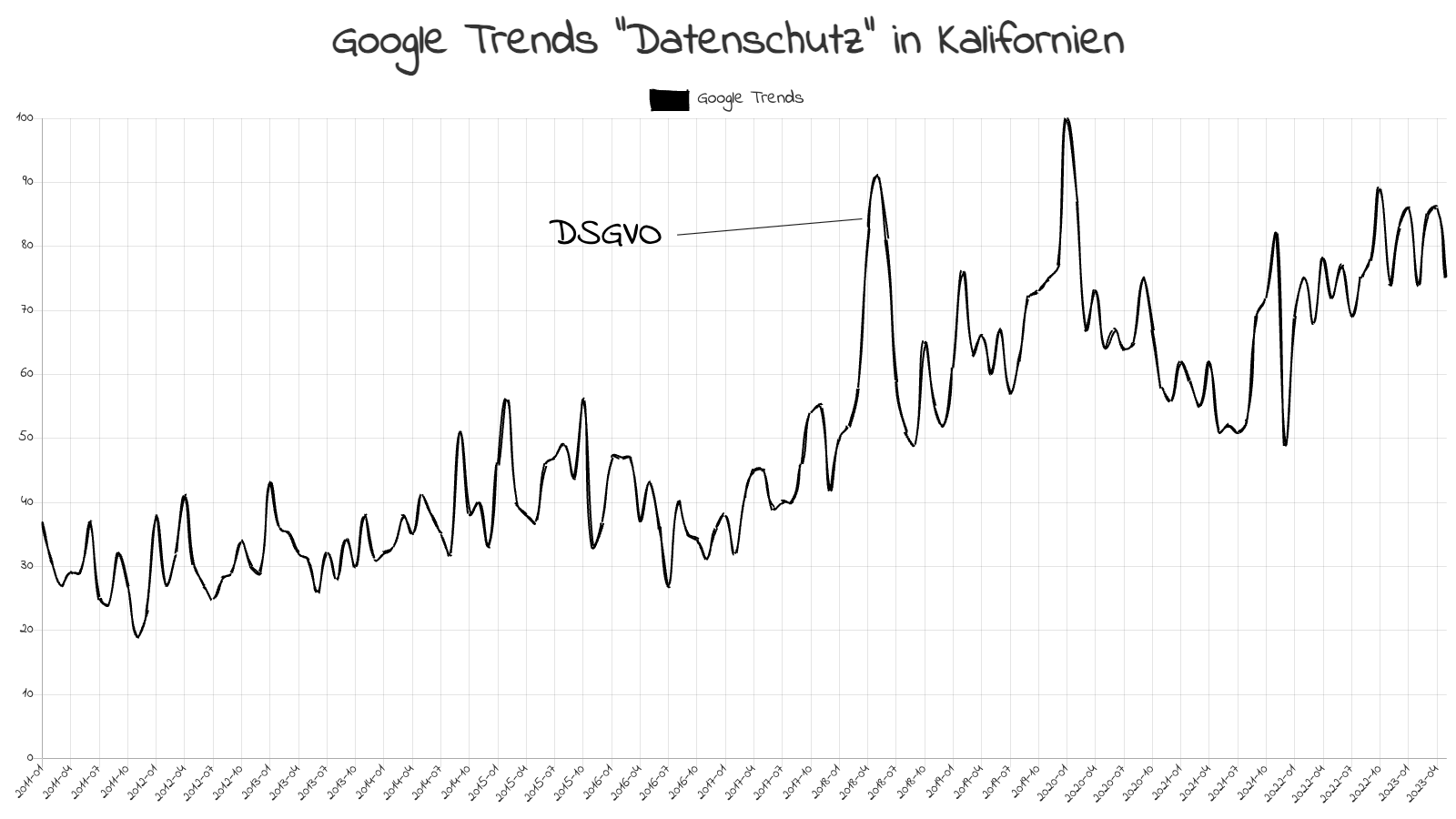
Heute geben selbst Kritiker zu, dass aus der DSGVO ist das geworden ist, was beabsichtigt war: ein Goldstandard für Datenschutz, an den sich jede ernstzunehmende, größere Software-Lösung hält. Auch aus den USA. Die DSGVO hat damit das eigentliche Ziel von Regulierung erfüllt, nämlich nicht einfach Dinge verboten, sondern eine Richtung vorgegeben. Seit der DSGVO machen sich Softwarebauer schon beim ersten Prototypen Gedanken um Datenschutz – viel mehr noch als vor zehn Jahren. Google arbeitet intensiv an Alternativen zu den unbeliebten Cookies, Apple hat sich Datenschutz sogar in die Mission geschrieben. Regulierung fördert die Forschung und Entwicklung.
Die Kritik der Unternehmen, die reguliert werden, rührt daher, dass das nicht die Richtung ist, in der sie eigentlich forschen wollen.
OpenAI entwickelt zum Beispiel gerade ein KI-Tool, das herausfindet, welche Teile eines Sprachmodells zur Antwort beitragen haben. Das klingt erst mal abgedreht – eine KI, die eine andere KI erklärt – ist aber eine mögliche Antwort auf die Forderung nach „Erklärbarkeit“. Gerade sind solche Prototypen nur Nebenschauplätze. Die Ansicht der EU ist nun: es gibt nichts Wichtigeres. Bevor wir die KI-Werkzeuge schneller und mächtiger machen, müssen wir uns die Köpfe darüber zerbrechen, dass sie auch das Richtige tun.
Ich glaube, die Macher des Gesetzes haben damit recht. Das Problem ist einfach, dass der Rest der Welt das nicht so sieht.
-
Wie der IT-Rechtsberater Christian Schwerdt erklärt, kann laut dieser Definition sogar Microsoft Excel als Hoch-Risiko-Ki zählen – wenn die Datei beispielsweise über die Bettenbelegung in einem Krankenhaus entscheidet. ↩︎
-
Während einer Anhörung zur KI-Regulierung in den USA gab der zuständige Senator zu, dass der Kongress den Zeitpunkt einer Social-Media-Regulierung eindeutig verpasst habe (Quelle ↩︎
Kommentare
Keine Kommentare vorhanden. Sei der Erste, der einen Kommentar hinterlässt!